“If you are not paying for the product, then you are the product”.
This is a common saying when referring to online services that are offered for no financial payment (“free”).
The reason is that they often collect some personal data about you or your use of the service that the provider then can sell to the online advertising and marketing industry for payment. The payment they get for this covers the cost of providing the service to you and also allows for a profit to be made.
And so, they earn their money, and the app users are their product.
However, it is common knowledge that companies like Google and Facebook use our personal data for targeted advertising. The personal data collected is anonymized and often aggregated to produce larger data sets, which enable them to target individuals or groups based on common preferences — for instance that they live in a certain location or like to drink coffee.
The idea that your data is anonymized might provide some comfort.But because of smartphones and the smartphone software applications (“apps”) many people use, companies can collect a large range of types of data and so trace individuals without asking for personal details such as your name. An example of this type of data is your smartphone unique identifier (IMEI-number1), and IP-address (when connected via WiFi).
Combined with your email address, GPS data, app usage etc., it is possible to identify specific individuals -– namely you!
Exposing the AdTech industry
To investigate this issue, The Norwegian Consumer Council (NCC), a government funded organization representing consumer interests in Norway, published a groundbreaking report last year about how the online marketing and AdTech (Advertising Technology) industry operates.
The report’s title immediately raised the flag: “Out of Control” (OuC)2. And the subtitle outlines the findings: “How consumers are exploited by the online advertising industry”.
The report tested and analyzed 10 popular “apps” under the umbrella “social networking apps”, and the findings were concerning. Most users of such apps know that registering your personal data is optional, and after the introduction of the GDPR every app is careful to ask for your consent and encourages you to click OK to accept their Privacy Policy.
What many users will not know is how much and how far the personal data is distributed. Only a few users will be aware that clicking OK implies that your data is fed into the huge AdTech and MarTech industry, which is predicted to grow to USD 8.3 billion in annual revenues by 20213.
The players in this industry are giants such as Amazon, Facebook, Google and Twitter. If that was not enough, both iOS (Apple) and Android (Google) have their ways to track consumers across different services.
Apple being more privacy minded than some others have recently developed options to allow the user to reset the “unique” advertising identifier in devices and also stop tracking across WiFi networks to break the identification chain and make it harder to target a specific user.
But the industry also has a large number of third-party data and marketing companies, operating quietly behind the scenes.
The far-reaching consequences of AdTech
This is what the NCC’s report is about, and the findings are concerning:
The ten apps that were tested transmit “user data to at least 135 different third parties involved in advertising and/or behavioral profiling” (OuC, page 5).
A summary of the findings is presented on OuC page 7, and here we find social networking apps, dating apps and apps that are adapted to other very personal issues (for instance makeup and period tracking). The data that is gathered can include IP address, GPS data, WiFi access points, gender, age, sexual orientation, religious beliefs, political view, and data about various activities the users are involved in.
This means that companies are building very detailed profiles of users, even if they don’t know their names, and these data are sent to for instanceGoogle’s advertising service DoubleClick and Facebook. Data may also be sold in bidding processes to advertising companies for targeting advertising.
It is one thing to see ads when you perform a Google search, but it’s quite another to be alerted on your phone with an ad while you are looking at a shop’s window display, or passing a shop selling goods the advertiser knows you are interested in. Scenarios like these are quite possible, if you have clicked “OK” to a privacy policy in an app.
Personalized directed ads are annoying, but even worse is that the collection and trade of personal data could result in data falling into the hands of those who may then target users with insults, discrimination, widespread fraud, or even blackmail. And there is clear evidence that personal data have recently been used to affect democratic elections4.
What happened after The Norwegian Consumer Council published “Out of Control”, will be covered in our next blog post, but we can reveal that one of the companies studied had a legal complaint filed against them for violating the GDPR and is issued an administrative fine of € 9.6 million.
So stay tuned!
References:
IMEI stands for International Mobile Equipment Identity.
2020 was a very challenging year for many people around the world, and especially as a consequence of the ongoing global health situation. As we begin a new year we think about all those who have been impacted by the COVID-19 pandemic.
At the same time it is important that we don’t forget about other global challenges, and as Runbox celebrated 20 years in 2020 we naturally considered the current state of the environment compared to the year 2000.
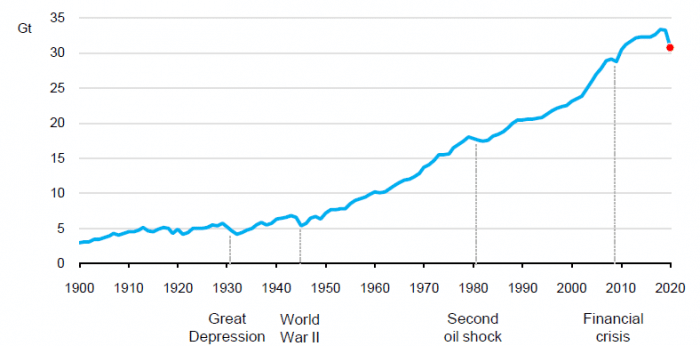
Since the year Runbox was founded, global energy-related carbon dioxide emissions have increased over 40% from approximately 23 to 33 gigatons as illustrated by the figure below.
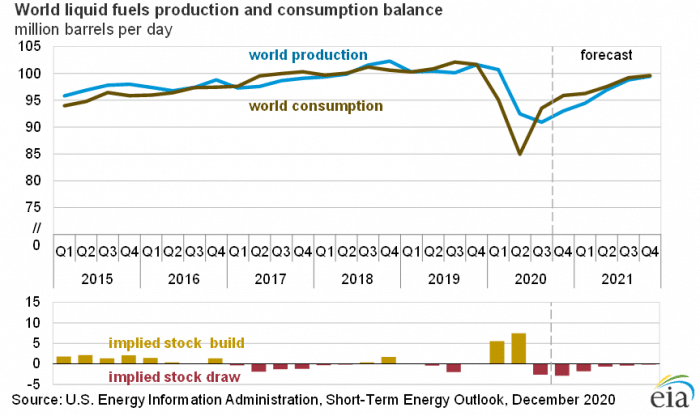
There was a significant increase in emissions over the past year, and despite the pandemic-related drop during 2020 world liquid fuels production and consumption is forecast to continue nearly unabated in 2021 and beyond.
Source: US EIA (https://www.eia.gov/outlooks/steo/)
It is clear that the global environmental crises in all likelihood remain the most essential and existential challenges facing mankind, and that 2020 only represents a temporary interruption.
GDPR in the Wake of COVID Spread: Privacy under Pressure – Part 2
Our previous blog post in this series concerned mobile phone applications under development, or already developed, in various countries for tracing the spread of COVID-19 infections. In particular the blog described the situation in Norway, and we expressed our concerns, but also our trust, in the fact that The Norwegian Data Protection Authority (‘Datatilsynet’) would be on the spot to safeguard privacy – as regulated by strictNorwegian privacy regulations.
The Norwegian Data Protection Authority — more than a watchdog
The Norwegian Smittestopp app
We were right, and we are proud of the intervention by the Norwegian Data Protection Authority (NDPA), which in June banned the Norwegian COVID-19 tracker app Smittestopp. The ban illustrates NDPA’s independency, and that NDPA has legal power to enforce privacy protection when public (and private) organizations violate the law.
This power is anchored in the Personal Data Act (personopplysningsloven), the Norwegian implementation of GDPR, and the Personal Data Regulations (personopplysningsforskriften).
After evaluating the app Smittestopp as it was implemented in April this year, NDPA concluded that the app violated the privacy legislation in mainly two respects:
The app was not a proportionate intervention of the user’s fundamental right to data protection.
The app was in conflict with the principle of data minimization.
On June 12, The NDPA notified The Norwegian Institute of Public Health (NIPH) that the app would be banned, which was confirmed on July 6. Consequently, NIPH immediately stopped collecting data from the around 600,000 active users of the app, and deleted all stored data on their Azure server.
What the requirement for proportional intervention means
The breach of the requirement for proportional intervention concerned the expected low value of the app regarding infection tracking, due to the relatively small number of the population in the testing areas actually using the app (only 16%).
The reason for the breach of the principle of data minimization was that the app was designed to cover three different purposes:
Movement tracing of individuals (for research purposes).
Spread of the infection among the population.
The effectiveness of infection control measures.
The NDPA was also critical to the app because it was not possible for the users to choose for which of the three purposes their data would be used.
A new app is already being planned
The government has decided to terminate further development of Smittestopp, and will instead focus on the development of a new app. After seeking advice from NIPH, the government has decided to base a new app on the Google Apple Exposure Notification (GAEN) System, or ENS, which they call “the international framework from Google and Apple” because many countries (for instance Denmark, Finland, Germany, Great Britain) are going “the GAEN way”.
Important arguments for the government’s decision are that GAEN supports digital infection tracking only (Bluetooth-based), involves no central data storage, and includes the possibility to exchange experiences and handle users’ border crossings. In the meantime the EU has implemented a recommendation for decentralized Corona tracking applications, putting GAEN “squarely in the frame“.
NIPH was given the task to specify a request for proposal in an open competition for the development assignment of the new app, and now (October 20) the Danish Netcompany is hired to do the development. Netcompany has a similar contract with the Danish health authorities, and was the only bidder (!). The new app expected to be implemented this year (2020).
The privacy debate continues
Three main issues are still being debated, and the first is technical: Is Bluetooth reliable enough? Experiences show that false positives, but also false negatives, do occur when Bluetooth is being used.
The second issue is of course privacy. Even if personal data is stored locally on the phone, notifications between phones have to be relayed through a network – so what about hacking? In addition, Trinity College in Dublin has uncovered that on Android phones, GAEN will not work unless it is sending owner and location information back to Google.
The Norwegian Data Protection Authority published a report on digital solutions for COVID-19 (‘Coronavirus’) infection tracking on September 11 this year. The report was developed by Simula Research Laboratory, who did not bid on the contract for the new GAEN-based application (arguing that they are a research institution and not a software development company).
The report “… focuses on efficiency, data privacy, technology-related risks, and effectiveness for government use. In terms of privacy and data protection, the report notes that if location data is still stored by Google, the COVID-19 app Smittestopp would be less privacy intrusive than the GAEN one.”
Conclusion
We will conclude with a quote (in our translation): “There is no perfect solution for digital infection tracking. Effective infection control and privacy stand in opposition to each other.”
For us at Runbox, privacy is priceless, and we are still wondering if the pros outweigh the cons.