
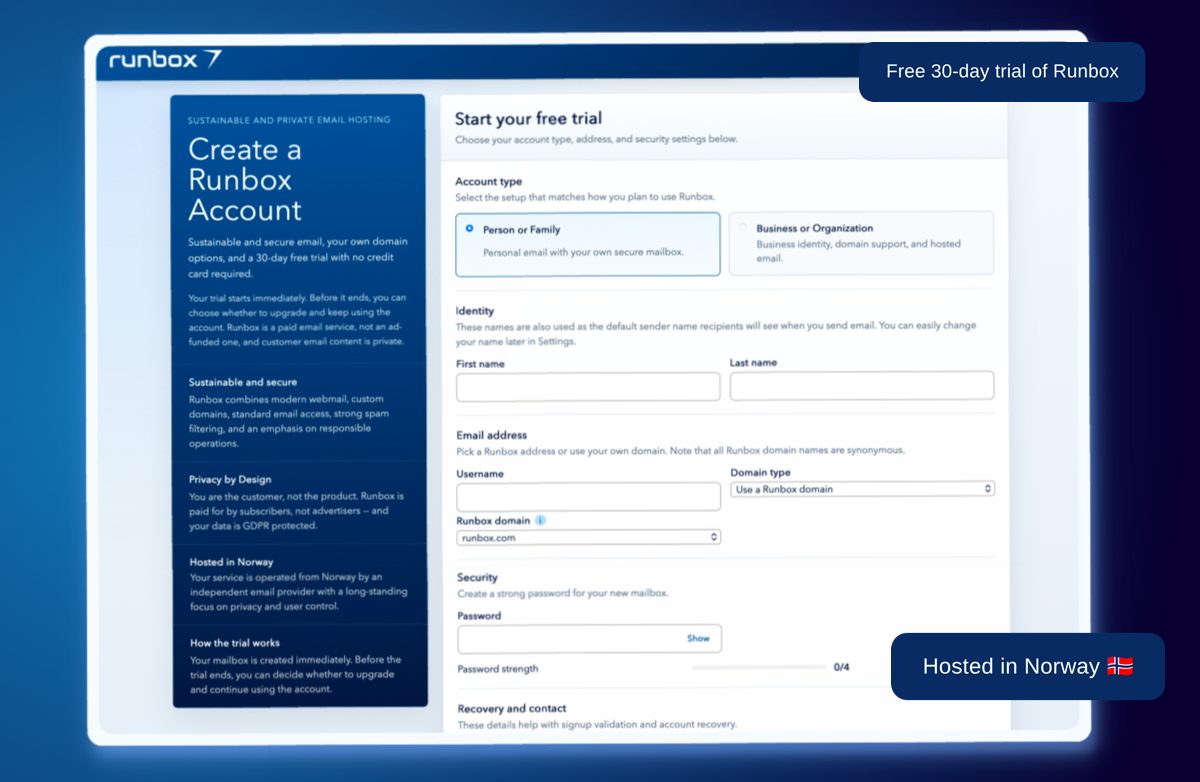
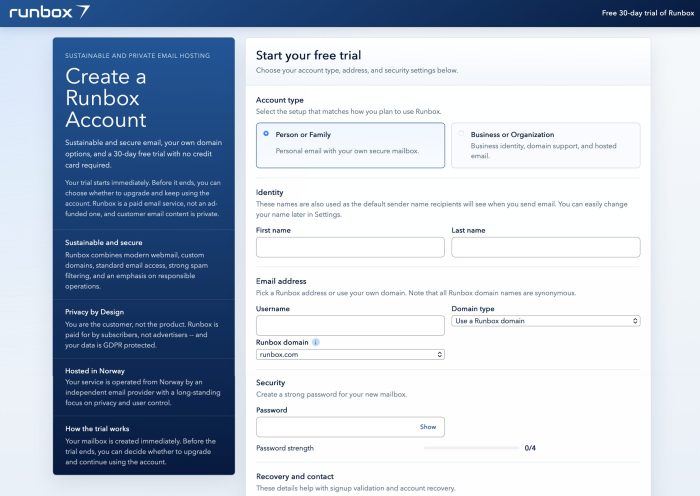
It’s been a while since our last Runbox 7 update post, and we wanted to share what we’ve been working on behind the scenes. Some of these are small quality-of-life improvements, a few are bug fixes that should make daily use smoother, and others are bigger updates to areas like payments and to our underlying framework — setting the stage for more updates in the near future.
💡 To enable the new features, please ensure that Runbox 7 is updated by reloading it in a web browser or restarting it on your phone.
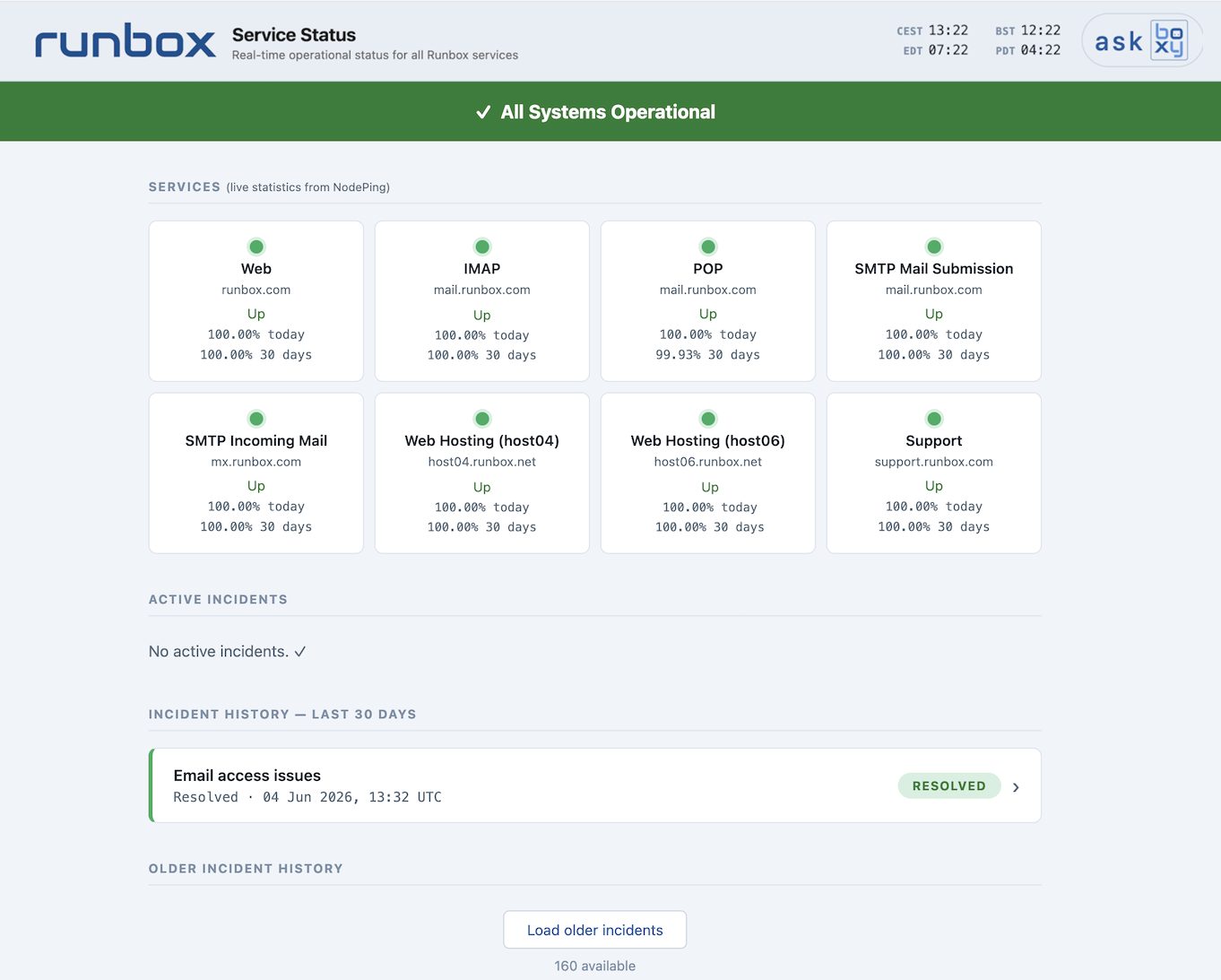
Updated Status Page
We have given our status page a fresh new look at status.runbox.com. An important change is that the latest updates now appear at the top of each incident post so that we can communicate better. Previously new updates were added at the bottom, and it was easy to miss updates unless you actively clicked through. The page shows live service status at a glance, with a colour-coded banner indicating overall health. Timestamps across four time zones let you always know what’s happening no matter where you are. The new status page also integrates with Boxy, our support assistant, which can answer service-status questions directly.

Across Europe, conversations are taking place about reducing dependence on US tech and moving towards European technology solutions. In a world which at times feels like it has shifted on its axis, it’s becoming clear that this movement is about more than just technology. The shift away from US tech is about reducing reliance and protecting infrastructure, but also about protecting the fundamental principles that define us as a society. Europe’s focus on data privacy, transparency, and democratic values can often feel in direct conflict with the US approach. In this article, we look at what’s at stake and what Europe is doing about it.


Understanding what they are — and what they are not
At Runbox we’ve been thinking a lot about what we hear in the news about Artificial Intelligence (AI) and what that means for us as individuals, as a privacy conscious business and for our customers. We’ve had many discussions and debates on this topic and whether we could, should or even can use AI to improve what we do.
For many years our website has stated that:
“We believe that communication is a fundamental principle, and inherently good.”
Communication, done well, builds understanding and brings people together. That matters to us.
With that in mind we started to try and understand where AI might fit into what we do and where it can’t, or shouldn’t play a part.


This Earth Day, the theme “Our Power, Our Planet” reminds us that real change starts with the choices we make every day. Email is no exception: the average email generates about 4g of CO₂, and those with attachments can emit up to 50g—adding up to 410 million tons of CO2 from emails every year. Data center energy demands grew 12% over the last 5 years, with AI being a major driver, and most of these facilities still rely on fossil fuels to power our digital lives.

At Runbox, we believe in the power of individual and collective action. That’s why we’ve built an email service that runs on 100% renewable energy and double offsets for any remaining emissions, making your inbox not just private, but truly carbon-negative. While big tech grapples with rising emissions and vague sustainability claims, we’re transparent about our impact and committed to real change.
This Earth Day, take control of your digital footprint. By choosing Runbox, you’re not just sending emails—you’re supporting a movement for a cleaner, more ethical digital future. Together, we can turn “Our Power, Our Planet” into action, one email at a time.
🌱 Try Runbox free for 30 days.

As a Norwegian company, Runbox is occasionally asked how the U.S. CLOUD Act affects our users—and the answer is simple: it doesn’t. Unlike U.S.-based providers, we own our servers and operate under Norwegian law, ensuring your emails and personal data are fully protected by Norwegian law and GDPR. The CLOUD Act has no jurisdiction over Runbox or your information. Read on to learn how we keep your data safe.


At Runbox, we’ve spent the last 25 years operating on the principle that technology should serve humanity—not exploit it. Our commitment to sustainability, privacy, and transparency represents a core principle that defines how we serve our customers. This dedication has earned us the Ethical Consumer Best Buy designation since 2020, a rigorous independent recognition of our responsible and sustainable business practices.

Our approach stands in contrast to an industry that too often prioritizes profit over people. Many tech companies don’t just use your data—their entire business models rely on it, exploiting personal information at the expense of your privacy, the environment, and even democratic values. This unchecked collection and monetization of personal data doesn’t just undermine privacy—it erodes trust in digital systems, harms the environment through unsustainable practices, causes societal and psychological harm, and undermines the democratic values that protect individual freedoms. We believe technology should—and can—do better.
(more…)
Summary
On March 4th, our email services experienced a critical incident caused by a cascade of unforeseen hardware failures. Multiple SSD (Solid-State Drive) disks failed in quick succession resulting in an application server becoming unresponsive, first impacting email services for some users and then spreading to other parts of the system.
Users who were already logged in to webmail experienced fewer disruptions, but new logins and IMAP connections were significantly impacted. Our support system also lost operability during the outage.
We have since replaced the failed hardware, rebuilt the affected systems, and fully restored services with additional redundancy. No user data was lost, and we have taking immediate and longer-term steps to prevent a recurrence in the future.
(more…)
Recent reports reveal that some companies are handing over user data when served with a subpoena by authorities. At Runbox we monitor this trend with concern and want to take the opportunity to make it clear that we will not disclose user data to anyone unless certain very specific and stringent criteria are met.
A subpoena, warrant or request from any government or foreign agency is not enough to meet our requirements. If an entity requests access to any user data, Runbox will by principle respond by requesting a Norwegian court order pursuant to the Norwegian Criminal Procedure Act before disclosing any information.
Read on to learn how Norwegian privacy law protects your data and why it’s your best defense.


As a privacy-focused email service based in Norway, we believe that protecting the right to privacy isn’t just about safeguarding data. It’s also about defending the very essence of democracy. Privacy and free expression are what let us speak freely, challenge authority, and engage in society without fear – democracy can’t thrive without them. And without our active participation, the structures that uphold our freedoms lose their strength, and the principles we value start to disappear.
Without privacy, how safe is your right to speak your mind? How fair is the system if your personal information can be used against you? How free are you to take part in your community if you’re always looking over your shoulder? Privacy isn’t just another right – it’s the cornerstone that protects all our other rights.
Because democracy is more than just the rule of law, free and fair elections or independent courts. It is also about the right to privacy. When privacy is weakened, everything else we value in a democracy starts to wobble. That’s why we at Runbox don’t just see privacy as a feature – we see it as a commitment to the principles that keep societies open, fair, and free.
