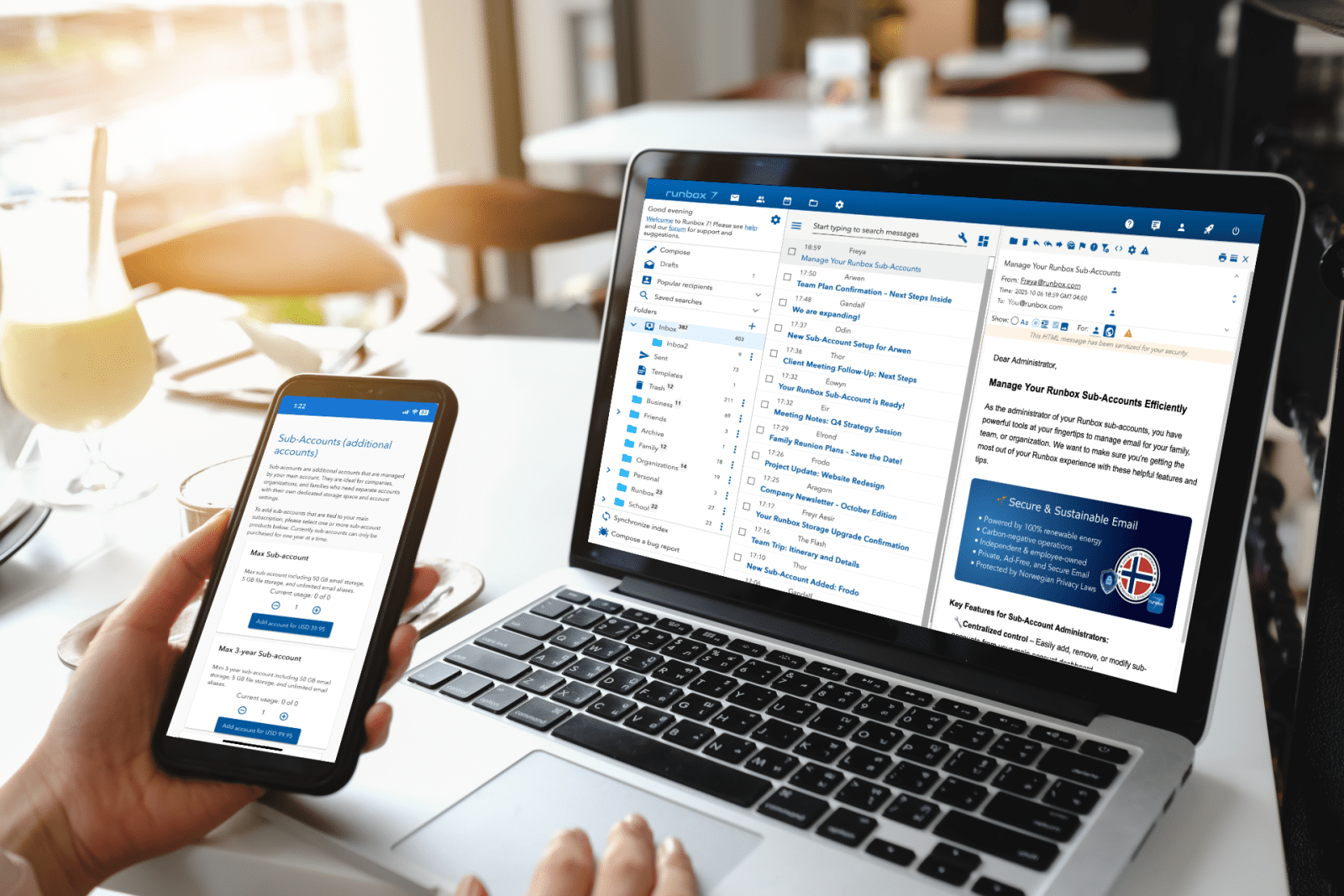
In late 2025, reports emerged that Google had enabled its Gemini AI by default for Gmail, Chat, and Meet users, allowing it to analyze private communications – often without explicit user consent. While Google maintains that Gmail content is not used to train its public Gemini AI models, it can still scan and process emails, attachments, and other data for personalization features like summarizing and drafting replies.
The controversy centers on how this access was enabled by default, the lack of clear user notification, and the complexity of opting out, sparking concerns about privacy and transparency. Here’s what’s happening, why it matters, and what you can do.