The internet has transformed how we communicate, access information, and connect with each other, but it’s also brought new challenges, particularly when it comes to distinguishing fact from fiction. As misinformation and disinformation spread rapidly across social media and other online outlets, telling truth from fiction is becoming increasingly difficult. And while fact-checking is crucial for ensuring the accuracy of information, some will argue that fact-checking and content moderation is nothing but censorship and a threat to free speech. This raises important questions about the role of online platforms in fact-checking and moderating content, and what responsibility they have to their users. In this article, we’ll explore where fact-checking stands today, how platforms are handling content moderation, and the impact these changes are having.
The influence of big tech companies on our lives is undeniable. With limited oversight and a focus on maximizing profits, these corporations have become increasingly powerful. They rely on unrestricted access to our personal data to maximize profits, which puts them at odds with any form of regulation. They actively seek to shape policies that protect their lucrative revenue streams, and resist regulatory measures that could limit their power.
Without accountability, big tech companies put profits ahead of our privacy. They leave us vulnerable to misinformation and bias, and contribute to the shaping and manipulation of public opinion. As the digital world continues to develop, we’re likely to see more attempts to deregulate to protect their bottom lines.
Climate change and environmental degradation are among the most critical challenges facing the world today. The year 2024 stood as a stark reminder of the pressing and escalating environmental and climate crises. From record-breaking temperatures to intensified natural disasters, the year’s events underscored the urgency of global action.
By participating in this conversation, we hope to contribute to raising awareness about the accelerating impacts of climate change, biodiversity loss, pollution, and deforestation. This blog post captures the key environmental and climate-related developments of 2024, supported by data, illustrations, and sourced information.
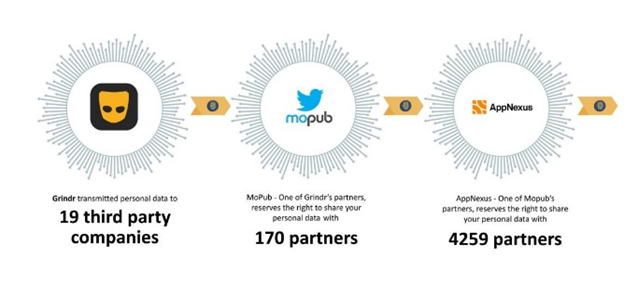
Oslo District Court has found Grindr’s sharing of personal data illegal as a result of the Norwegian Consumer Council complaint from 2020. Accordingly, Grindr has to pay EUR 5 million, as fined by the Council.
Our guardians of personal data and privacy: NDPA, NPAB, and NCC
As we have written multiple times in our blog series about GDPR and consequences of this EU-regulation, Norway has a long history of protecting citizens’ personal information. It started out with the first Personal Data Act implemented in 1978 with the purpose of protecting the individual against privacy being violated through the processing of personal data. The law was updated with GDPR clauses in the year 2000.
In 1980, the Norwegian Data Protection Authority (NDPA) was established as an independent authority whose task is to monitor compliance with the Personal Data Act. It is important to note that the NDPA has two roles: supervisory authority and ombudsman.
The NDPA decisions may be appealed to NPAB, Norwegian Privacy Appeals Board (Personvernnemda), whose decisions are final.
During recent years, another Norwegian governmental public body, the Norwegian Consumer Council (NCC), whose role is to protect consumers’ interests, has become involved in privacy, more precisely the misuse of personal data that big tech companies are involved in. As a governmental-independent agency, the NCC is free to chose the cases they want to work on.
Sharing of personal data is illegal without specific consent: The Grindr case
Recently, the NCC has put effort into the task of preventing the big tech companies from using personal information for surveillance-based marketing that the users have not consented to. Neither have users given consent to how personal data is transmitted to the companies’ partners.
The year 2023 was marked by significant environmental and climate-related events that underscored the urgent need for collective global action. From escalating greenhouse gas emissions to unprecedented weather extremes, the planet experienced alarming signs of environmental degradation and climate disruption. This blog delves into the most pressing issues of 2023, accompanied by illustrations and sourced data to shed light on the state of our environment.
Rising Carbon Emissions
Despite global efforts to curb carbon emissions, 2023 saw a continued increase in atmospheric CO₂ levels. According to the Mauna Loa Observatory, CO₂ concentrations peaked at 424 parts per million (ppm) during the year, a stark reminder of the relentless upward trajectory.
Key Contributors:
Energy Sector: Fossil fuels continued to dominate global energy production, with coal consumption hitting record highs in some regions.
Deforestation: Large-scale deforestation in the Amazon and Southeast Asia contributed significantly to carbon emissions.
Industrial Activities: Rapid industrialization in emerging economies exacerbated emissions, outpacing efforts to transition to cleaner technologies.
2023 was a year of extreme weather events that affected millions of lives and ecosystems:
Heatwaves: Record-breaking heatwaves scorched parts of Europe, the United States, and Asia. Southern Europe saw temperatures surpassing 48°C, severely impacting agriculture and water resources.
Flooding: Catastrophic flooding displaced millions in Pakistan, Nigeria, and Italy, with damages running into billions of dollars.
Wildfires: Uncontrollable wildfires ravaged forests in Canada and Greece, releasing massive amounts of carbon and destroying biodiversity hotspots.
Biodiversity loss reached critical levels in 2023, with numerous species teetering on the brink of extinction. The International Union for Conservation of Nature (IUCN) reported that:
28% of species assessed were threatened with extinction.
Coral reefs, which host 25% of marine species, suffered extensive bleaching due to rising ocean temperatures.
Melting Ice and Rising Seas
The Arctic and Antarctic regions continued to lose ice at alarming rates in 2023. The National Snow and Ice Data Center (NSIDC) reported:
The Greenland ice sheet lost an estimated 400 gigatons of ice, contributing significantly to global sea level rise.
Antarctic sea ice reached its lowest extent in recorded history during the winter months.
Plastic pollution remained a critical issue, with over 8 million tons of plastic waste entering the oceans annually. The Great Pacific Garbage Patch expanded further, threatening marine life and ecosystems.
Efforts to Combat Plastic Waste:
Legislative Actions: Countries like Canada and the EU implemented bans on single-use plastics.
Innovative Solutions: Startups and NGOs developed ocean-cleaning technologies and biodegradable alternatives.
The environmental and climate challenges of 2023 serve as a stark reminder of the fragility of our planet. While progress was made in renewable energy and policy initiatives, the pace of degradation continues to outstrip solutions. Addressing these challenges demands an unprecedented level of global cooperation, innovation, and commitment from all sectors of society.
What can you do? Educate yourself, advocate for sustainable policies, and make environmentally conscious choices in your daily life. The fight for our planet’s future requires all hands on deck.
Runbox takes a clear stand against big tech companies’ use of personal information for advertising purposes, and we are critical of their huge influence on society in general.
At the same time, we are proud of the Norwegian government agencies’ effort to crack down on companies breaking privacy legislation, by applying the legislation provided by the EU’s GDPR (General Data Protection Regulation).
This monitoring of privacy has its roots as far back as 1978 when Norway, as the second country in the world (shortly after Sweden), adopted a law on the processing of personal data, and established Datatilsynet (the Norwegian Data Protection Authority; NDPA).
For instance, in October 2022 we wrote about Google Analytics (GA) vs privacy, following up with a blog post about action taken by NPDA towards a Norwegian company’s use of GA, which implies unlawful transfer of personal data to the United States via GA.
In 2021 we published a couple of blog posts about reports from Forbrukerrådet (the Norwegian Consumer Council; NCC) about how the extensive AdTech and MarTech industry use personal data for targeted advertising.
NDPA was then prompted (by NCC) to impose a fine of NOK 65 mill (approximately USD 6,5 mill) on the dating app Grindr for breaching the consent requirement in the GDPR. (Read our update on 30 September 2023 on the Grindr case here.)
The Norwegian DPA case against Meta – and personal data as a commercial product
Meta Platforms Ltd is the umbrella organization that owns Facebook, Instagram, WhatsApp, and more. Currently, the Norwegian DPA has a lawsuit going against Meta Platforms Ireland Ltd and Facebook Norway AS, because of illegal behavioral advertising where they use personal data they are not allowed to for such purposes [source, source] according to the GDPR.
When they (as do Google and other tech companies) are using personal data for targeted advertising, it creates plenty of opportunities for advertisers to pay and get your personal information in return. [source].
In addition, they share the access to users’ data with other tech firms when doing business together, for instance Facebook argues that such firms are essentially an extension of itself, defined as “service providers” or “partners” [source, source, source, source].
If that weren’t enough, real-time bidding (RTB) results in the average Norwegian internet user’s data being shared 340 times per day, according to a study from the Irish Council for Civil Liberties (ICCL) [source]. The fact that personal data has become commercial merchandise could be a theme for a separate blog post, but for now we’ll stick to what the headline indicates.
The NPDA has taken a leading role and has been involved in this legal issue for many years precisely because it has such major implications for Norwegians’ privacy. [Source: Datatilsynet]
Meta’s gliding flight for legal use of personal data in their advertising business
The NDPA versus Meta is the provisional culmination of a long process starting in May 2018, the day after GDPR came into force in the EU.
At that time the Austrian non-profit European Center for Digital Rights (NOYB) filed four complaints against respectively Google (Android), Facebook, WhatsApp and Instagram over “forced consent”: The services would not be accessible if users declined to agree to their terms of use [source], which is a breach of GDPR Article 6.
The complaint against Meta was lodged on 25 May 2018 to Österreichissche Datenschutzbehörde [source] who transferred the complaint to Facebook Ireland Ltd on behalf of the data subject from Austria.
Because Meta’s regional headquarters in Dublin is serving European countries, it is the Irish Data Protection Commission (DPC) who is Meta’s lead European data privacy regulator (Lead DPA).
Since the NOYB’s complaints in 2018, the cases have been through the European Data Protection Board (EDPB) and the Court of Justice of the European Union (CJEU), where the conclusion is unanimous: Meta can’t use personal data for targeted advertising based solely on its Terms of Service (ToS). The GDPR’s Article 7, Recital 32, Recital 42, and Recital 47 make this very clear.
The apple of discord has been whether Meta uses the correct basis for processing personal information when they collect data about what users do on the platform, and use it to display targeted advertising. The dispute is about the term contractual necessity, legitimate interest, and consent, referring to GDPR Article 6.
Meta first argued towards the Irish DPC, that contractual necessity, as stated in Facebook and Instagram ToS from 2018 (after introduction of GDPR), was a sufficient legal basis for its advertising business – claiming that users of Facebook and Instagram are in contract with Meta to receive targeted ads. This actually means that Meta admits that behavioral advertising is a core service [source].
The penalty of EUR 390 million was decided because the contractual necessity in Meta’s ToS as legal basis for targeted ads was deemed in violation of the GDPR. However, Meta’s move to argue legitimate interest did not help, even when Meta provided an “opt-out tool”. Under the GDPR Articles 21(1) and (2), users have the right to object to companies claiming that they have a “legitimate interest” in the processing of their personal data.
Then on 7 February 2019, the German Federal Cartel Authority (“Bundeskartellamt”), with support from the German Consumer Rights Organization (“VZBV”), entered the arena. They brought into the game the German competition legislation with a decision arguing that Meta’s terms of use for Facebook violated German legislation due to the abuse of a dominant market position by Facebook merging and utilizing the data in user accounts.
Facebook’s terms were said to violate the GDPR, as using Facebook required that Meta could collect and process user data from various sources without actual user consent. On this basis Bundeskartellamt prohibits Facebook from combining user data from different sources — Facebook-owned services and third party websites included.
In the case between Germany and Meta that followed, the Higher Regional Court, Düsseldorf (Oberlandesgericht Düsseldorf), put the case forward to the CJEU which decided on 4 July 2023 that legitimate interest (referring to Article 6 (1f)) is not adequate for targeted advertising, and that the user’s explicit consent is necessary to be in line with the GDPR. With this, the CJEU agreed with noyb, and Meta is not allowed to use personal data beyond what is strictly necessary to provide its core social media products.
That said, the CJEU recognizes that legitimate interest may be used as basis for direct marketing processing, but this argument will not outweigh the interests and rights of individuals.
The Irish DPC is dragging its feet?
Here we have to mention that the Irish DPC has been unwilling to fully support the claim that Meta violates the GDPR regarding their targeting advertising. Instead, they (on 6 October 2021) in their draft decision, initially sided with Meta and put the light on Meta’s lack of transparency, and thereby violation of the requirements of the GDPR (Article 12 and 13c). According to this, the Irish DPC proposed a modest penalty of EUR 28–36 million.
Following the GDPR procedure, the draft decision was sent to the other DPAs within EU/EEA who may have a legal interest in the decision. Ten of 47 raised objections against the DPC’s reasoning that the personalized service could legally include personalized advertising. The disagreement led the Irisih DPC to refer the point of dispute to the EDPB.
As referred above, the EDPB took the view that Meta Ireland could not rely on contractual necessity as legal basis for their targeted advertising, and due to the binding decision by EDPB 5 December 2022, the Irish DPC had a month to reach a final decision.
The story didn’t end there, as is explained in the 12 January 2023 EDPB press release where the Irish DPC is instructed to issue a tenfold penalty increase – both because of lack of transparency and breach of the GDPR – on Meta Ireland to €210 million in the case of Facebook and €180 million in the case of Instagram [source]. The Irish DPC then had to follow the EDPB instruction as it did on 31 December 2022 regarding Facebook and Instagram.
In the binding decision the EDPB also directed the Irish DPC to conduct a fresh investigation into Facebook and Instagram regarding the different personal data they collect, hereunder to assess whether processing of sensitive data is taking place [source].
The Irish DPC did not agree and said that “the DPC considers it appropriate that it would bring an action for annulment before the Court of Justice of the EU in order to seek the setting aside of the EDPB’s directions” [source]. And so it has done. The details are not known per 23 March 2023 [source], but the claims probably refer to Article 263 of the Treaty on the Functioning of the European Union, which allows the CJEU to examine the legality of the legal acts of bodies, offices or agencies [source].
The Irish DPC is Lead DPA for many Big Tech companies [source]. Click image to view full size.
The Irish DPC has been criticized as a bottleneck of enforcement regarding GDPR cross-border complaints concerning the 8 big tech companies (Meta, Google etc.) that have their European headquarters in Ireland. According to the report by the Irish Council for Civil Liberties (ICCL), and adding the new cases since the report was published, some 80 % of all cases have been overruled by the EDPB with demands for tougher enforcement action.
Back in 2020 the Austrian non-profit European Center for Digital Rights (NOYB) filed an open letter to the EU authorities that brought the Irish DPC’s weaknesses to light, referring to secret meetings between Meta and the Irish DPC to find ways to bypass GDPR requirements [source].
For the sake of balance we will refer to an article in The Irish Times where The Irish Data Protection Commissioner Helen Dixon defended the work of the DPC, and rejected claims that Ireland is a ‘bottleneck’ for enforcement [source].
The Norwegian DPA is taking action and imposes daily fines
The Irish DPC’s delay in the Meta case has triggered the Norwegian Data Protection Authority to intervene: On 14 July 2023, the Norwegian DPA notified Meta that they may decide to impose a coercive fine of up to NOK 1 000 000 (approximately USD 100 000) per day because of non-compliance with the GDPR’s Article 6, which in this case requires consent (ref. Article 6 (a)). Meta had until 4 August 2023 to either stop the use of personal data or receive daily fines.
On 4 August 2023 the NDPA put a temporary ban on Meta’s processing practice to use behavioral marketing. “Temporary” meant three months (from 4 August 2023), or until Meta showed that they had legally aligned themselves. That didn’t happen, the time limit was exceeded, and the NDPA did what they warned Meta about on 4 August by imposing a coercive fine of NOK one million per day [source], starting on 14 August, lasting until 3 November 2023.
It may seem strange that the NDPA can do this since Meta has its European headquarters in Dublin, and normally it is the Irish Data Protection Commission as Lead DPA that supervises the company in the EEA.
However, since NDPA’s concern is Norwegian users, they did this with reference to the GDPR Article 66 which allows data authorities to enact measures immediately when “there is an urgent need to act in order to protect the rights and freedoms of data subjects.” NDPA asked the Irish Data Protection Authority to impose a ban in May, but they didn’t, without saying why [source].
It follows that he decision from the Norwegian Data Protection Authority only applies to users in Norway.
Meta is taking the NDPA decision to Oslo District Court – and lost
It was no surprise that Meta didn’t accept the ban, and their reaction was to take the ban and the fine to Oslo District Court on 4 August 2023) , applying for a temporary injunction in an attempt to invalidate the decision. The reason: “This decision is invalid and causes significant damage to the company” [source].
“Meta Ireland and Facebook Norway have further stated that the decision is disproportionate, unclear, impossible to fulfill, contrary to other legislation (including the European Court of Human Rights, ECHR), and that it has already been fulfilled” [from the court’s ruling]. None of these statements were given weight, and Meta lost according to the court’s judicial ruling 6 September 2023.
In the court Meta stated that they would have to suspend Facebook and Instagram services in Norway to comply with the order. This seems strange, because in a blog post update 01 August 2023 they announced the following:
“Today, we are announcing our intention to change the legal basis that we use to process certain data for behavioral advertising for people in the EU, EEA and Switzerland from Legitimate Interests to Consent.”
It is to be noted that the UK is excluded, Norway is not mentioned, and not a word is said about when and how the change will take place (more on this below).
In addition to the case in the legal system, Meta has submitted several administrative complaints against the Norwegian Data Protection Authority’s decision. These processes are ongoing. [Source: NDPA won against Meta]
NDPA asks EDPB to make the ban permanent, also for the EU/EEA area
The Norwegian DPA is only authorized to make a temporary decision in this case, and the decision expires on 3 November 2023. Because of the urgency as stated by NDPA, they, according to a press release 28 September 2023, have asked the central European Data Protection Board (EDPB) for a European binding decision in the case against Meta.
In the request, the NDPA asked that the Norwegian temporary ban on behavioral advertising on Facebook and Instagram be made permanent and extended to the entire EU/EEA.
Referring to Meta’s announced intention to change the legal basis to consent, NDPA says in the press release: “It is uncertain whether and when a valid consent mechanism may be in place. The Norwegian DPA believes that we cannot tolerate illegal activity in the meantime.”
It is just about one month until the Norwegian ban expires, and one can only await the EDPB decision. It would seem strange if the EDPB decides against making the ban permanent, and that it is preferable that the GDPR should be interpreted consistently throughout the EU/EEA, and the rest of Europe as well.
Meta’s last move: “Pay for your Rights”
In September this year Meta proposed to GDPR regulators that they want to charge Europeans monthly subscriptions if they don’t agree to let the company to expose them to targeted advertising.
According to Wall Street Journal on 3 October, Meta hopes to roll out the plan – Subscriptions No Ads (SNA) – in the coming months for Europeans users. This will hit users with fees in the range of EUR 10 to 20 per month depending on platform used and also if the accounts covers mobile devices.
With this, Meta is trying a smart move to circumvent requirements for explicit consent before processing user data to select ads that are targeted. The company refers to some other companies, such as Spotify, who offers users a choice to avoid ads for a paid subscription. But there is a difference, as Techcrunch points out: Spotify has to pay to license the songs it delivers ad-free to subscribers, while Meta gets content from its users for free.
In addition, Meta has pointed to paragraph 150 in the recitals of CJEU’s 4 July 2023 decision that “… if necessary for an appropriate fee…” could be an alternative to users who decline to let their data be used for ad-targeting purposes, and that opens the door to a subscription service. However, as NOYB points out, these 6 words are not directly related to the case and should not be part of the binding decision – and as Max Schrems, founder and chair of the NOYB put it (quote):
“The CJEU said that the alternative to ads must be ‘necessary’ and the fee must be ‘appropriate’. I don’t think € 160 a year is what they had in mind. These six words are also an ‘obiter dictum‘, a non-binding element that went beyond the core case before the CJEU. For Meta this is not the most stable case law and we will clearly fight against such an approach.” (our text highlighting)
Per 3 October it is not clear if the Irish DPO will deem the SNA-plan compliant with the GDPR, and it is also a question whether the CJEU will stick to its ruling from 4 July 2023.
Here it is also worth mentioning that Meta’s advertising network will fall under the EU’s Digital Markets Act which requires user consent before mingling user data among its services, or combining it with data from other companies [source].
The case of Meta vs GDPR will obviously roll on.
The content of this article is intended to provide a general guide to the subject matter, and Runbox take no responsibility for its accuracy. It is advised that when using the information for any purpose other than personal that the sources provided are verified. Expert advice should be sought about your specific circumstances.
ADDENDUM: Why is it urgent to stop behavioral advertising?
“Meta, the company behind Facebook and Instagram, holds vast amounts of data on Norwegians, including sensitive data. Many Norwegians spend a lot of time on these platforms, and therefore tracking and profiling can be used to paint a detailed picture of these people’s private life, personality, and interests.
Many people interact with content such as that related to health, politics and sexual orientation, and there is a danger that this is indirectly used to target marketing to them.
“Invasive commercial surveillance for marketing purposes is one of the biggest risks to data protection on the Internet today”, head of international department at the NDPA Tobias Judin says.
When Meta decides which advertisements will be shown to a user, they also decide what not to show someone. This affects freedom of expression and freedom of information in a society. There is a risk that behavioral advertising strengthens existing stereotypes or could lead to unfair discrimination of various groups.
Behavioral targeting of political adverts in election campaigns is particularly problematic from a democratic perspective. Since tracking is hidden from view, most people find it difficult to understand.
There are also are many vulnerable people who use Facebook and Instagram that need extra protection such as children, the elderly, and people with cognitive disabilities.”
“Don’t tell anything to a chatbot you want to keep private.” [source]
Writing about AI in general and about chatbots specifically is like shooting at a moving target because of the speed of development. However, at Runbox we are always concerned about privacy and must examine the chatbots case in that respect.
Due to its popularity, we have mainly used ChatGPT from OpenAI as the target of our examination. NOTE: ChatGPT and the images from text captions DALL-E are both consumer services from OpenAI.
This blog post is a summary of our findings, leading to advice on how to avoid putting your privacy at risk when using the Natural Language Processing (NLP)-based ChatGPT.
Our examination is based on OpenAIs Privacy Policy, Terms of Use, and FAQ, and a number of documents resulting from hours of Internet browsing.
The blog post consists of two parts: PART I is a summary of our understanding of the technology behind language models in order to grasp the concepts and better understand its implications regarding privacy. In PART II we mainlydiscuss the relevant privacy issues. It is written as a stand alone piece, and can be read without necessarily have read PART I.
PART I: Generative AI technology
The basics
GPT stands for Generative Pre-trained Transformer, and GPT-3 is a 175 billion parameter language model that can compose fluent original writings in response to a short text prompted by a user. The current version of ChatGPT is built upon GPT-3.5 and GPT-4 from OpenAI.
ChatGPT was launched publicly on November 30, 2022. ChatGPT was released as a freely available research preview, but due to its popularity, OpenAI now operates the service on a freemium model [source].
The GPTs are the result of three main steps: 1) Development and use of the underpinning technology Large Language Models (LLMs), 2) Collection of a very large amount of data/information, and 3) Training of the model.
Let us also keep in mind that all this is possible only because of today’s advancements of computational power.
Language models
A language model is a system which denotes mathematics “converted” to computer programs that predict the next word/words in a sentence, or a complete sentence, based on probabilities. The model is a mathematical representation of the principle that words in a sentence depend of the words that precede them.
Since computers basically can only process numbers (in fact only additions and comparisons), text input to the model (prompts) must be converted to numbers, and likewise the output numbers have to be converted to text (response). Text in this context consists of phrases, single words, or parts of words called tokens.
When prompting a GPT then, your query is converted to tokens (represented by numbers), and used by the transformer where its attention mechanism generates a score matrix that determines how much weight should be put on each word in the input (prompt). This is used to produce the answer to the prompt, using the model’s generative capability – that is to predict the next word in a sentence by selecting relevant information from the pre-processed text with high level of probability of being fluent and similar to human-like text [source].
The learning part of the model is handled by a huge number of parameters representing the weights and also statistical biases for preventing unwanted associations between words. For instance, GPT-3 has 175 billion parameters, and GPT-4 is approximated to have around 1 trillion.
(The label “large” in LLM refers to the number of values (parameters) the model can change autonomously as it learns.)
Collecting the data
The texts the GPT model generate stems from OpenAIs scraping of some 500 billion words (in the case of GPT-3, the predecessor for the current version of ChatGPT) systematically from the Internet: books, articles, websites, blogs – all open and available information, from libraries to social media – without any restriction regarding content, copyrights or privacy.
The scraping includes pictures and program codes as well and is filtered resulting in a subset where “bad” websites are excluded
The pre-training process
All that data is fundamental for pre-training the model. This process analyses the huge volume of data (the corpus) for linguistics patterns, vocabulary, grammatic properties etc. in order to assign probabilities to combinations of tokens and combinations of words. The aforementioned transformer architecture is used in the training process, where the attention mechanism makes it possible to capture the dependencies between words independent of their position in a sentence.
The result of the pre-training process is an intermediate stage that has to be fine-tuned to the specific task the model is intended for, for instance providing texts, program code, or translation of speech as response to a prompt. The fine-tuning process uses appropriate task-specific datasets containing examples typically for the task in question, and the weights and parameters are adjusted accordingly.
Of cause, a ChatGPT-response to a prompt is not “burdened” with the ethical, contextual, or other considerations a human will perform. To prevent undesired responses (toxicity, bias, or incorrect information), the fine-tuning process is supervised by humans in order to correct inappropriate or erroneous responses, using prompt-based learning. Here the responses are given a “toxicity” score that incorporates human feedback information [source].
ChatGPT usage training
The learning process continues when response generated following by a user’s prompts is saved and subject to the training process, at least for 30 days, but “forever” if chat history isn’t turned off. In any event it is not possible to delete specific prompts from user history [source], only entire conversations
In the world of AI and LLMs, hallucinations are the word used when responses are like “pulled from thin air”.
OpenAI offers an API that makes it possible for “anyone” to train GPT-n models for domain specific tasks [source], that is to build a customized chatbot. In addition, they have launched a feature that allow GPT-n to “remember” information that otherwise will have to be repeated [source, source].
Takeaways
The huge volume of data scraped is obviously a cacophony of contents and qualities that will affect the corpus and so also the probability pattern and the responses produced [source].
ChatGPT has limited knowledge of events that have occurred after September 2021, the cutoff date for the data it was trained on [source].
The response you get from ChatGPT to your prompt is based on probabilities, and as such you have no guarantee of the validity [source].
A prompt starts a conversation, unlike a search engine like DuckDuckGo and Google that gives you a list of websites matching your search query [source].
ChatGPT uses information scraped from all over the Internet, without any restrictions regarding content, copyrights, or privacy. However, manual training of a model was introduced to detect harmful content [source]. Violations of copyrights has resulted in lawsuits [source], and also signing of more than 10 000 authors of an open letter to the CEOs of prominent AI companies [source].
Your conversation is normally used to train the models that power ChatGPT, unless you specifically opt-out [source].
PART II: Chatbot privacy considerations
The privacy considerations with something like ChatGPT cannot be overstated” [source]
The following introduction is mainly made for readers that have skipped this blog post PART I.
Generative AI systems, such as ChatGPT, use information scraped from all over the Internet, without permissions nor restrictions regarding content, copyrights, or privacy (more on this in PART II). This means that what you have written on social media, blogs, comments on an article online etc. may have been stored and used by AI companies to train their chatbots.
Another source for training of generative AI systems is prompts, that is information from users when asking the chatbot something. What you ask ChatGPT, the sentences you write, and the generated text as well, is “taken care of” by the system and could be available for other users through the answer of their questions/prompts.
However, according to Open AI’s help center article, you can opt-out of training the model, but “opt-in” is obviously default.
So, both the Internet scraping and any personal information included in your prompts can have as result that personal information could turn up in a generated answer to another arbitrary prompt.
This is very problematic for several reasons.
Is Open AI breaching the GDPR?
First, OpenAI (and other scraping of the Internet) never asked for permission to use the collected data, which could contain information that may be used to identify individuals, their location, and all kinds of sensitive information from hundreds of millions of Internet users.
Even if Internet scraping is not prohibited by law, it is ethically problematic because data can be used outside the context in which it was produced, and so can breach contextual integrity, which has de facto been manifested in the EU’s General Data Protection Regulation (GDPR) Article 6, 1 (a) as prerequisite for lawful processing of personal data:
…the data subject has given consent to the processing of his or her personal data for one or more specific purposes
Here language models, like Open AI’s ChatGPT, are in trouble: Personal data can be used for any purpose – a clear violation of Article 6.
Second, there is no procedures given by Open AI for individuals to check if their personal data is stored and thereby can potentially be revealed by arbitrary prompt, and far less can data be deleted by request. This “right to erasure” is set forth in the GDPR Article 17, 1:
The data subject shall have the right to obtain from the controller the erasure of personal data concerning him or her without undue delay …” on the grounds that “(d) the personal data have been unlawfully processed
It is inherent in language models that data can be processed in ways that are not predictable and presented/stored anywhere, and therefore the “right to be forgotten” is unobtainable.
Third, and without going into details, the GDPR gives the data subjects (individuals) regarding personal data the right to be informed, the right of access, the right to rectification, the right to object, and the right to data portability. It is questionable if generative AI systems can ever accommodate such requirements since an individual’s personal data could be replicated arbitrarily in the system’s huge dataset.
Fourth, Open AI stores all their data, including personal data they collect, one way or another, on servers located in the US. That mean they are subject to the EU-US Data Privacy Framework (see our blog Privacy, GDPR, and Google Analytics – Revisited), and the requirements set there.
To answer the question posed in the headline of this paragraph, Is OpenAI breaching the GDPR?It is very difficult to understand how ChatGPT, and other language models for generative use (Generative AI systems) as well, can ever comply with the GDPR.
What about the privacy regulations in the US?
Contrary to the situation in Europe, there is no federal privacy law in the United States – each state has their own jurisdiction in this area. There are only federal laws such as HIPAA (Health Insurance Portability and Accountability Act) and COPPA (Children’s Online Privacy Protection Act) which regulate the collection and use of personal data categorized as sensitive. However, there are movements towards regulation of personal information in several states as tracked by IAPP (The International Association of Privacy Professionals).
How do OpenAI use data they collect?
When signing up to ChatGPT, you have to agree to OpenAI’s Privacy Policy (PP), and allow them to gather and store a lot of information about you and your browsing habits. Of course, you have to submit all the usual account information, and to allow them to collect your IP-address, browser type, and browser settings.
But you also allow them to automatically collect information about for instance
“… the types of content that you view or engage with, the features you use and the actions you take, as well as your time zone, country, the dates and times of access, user agent and version, type of computer or mobile device, and your computer connection”.
All this data made it possible to build a profile of each user – bare facts, but also more tangible information such as interests, social belongingness, concerns etc. This is similar to what search engines do, but ChatGPT is not a search engine — it is a “conversational” engine and as such is able to “learn” more about you depending on what you submit in a prompt, that is, how you engage with the system. According to their PP and the citation above, that information is collected.
The PP acknowledges that users have certain rights regarding their personal information, with indirect reference to the GDPR, for instance the right to rectification. However, they add:
“Given the technical complexity of how our models work, we may not be able to correct the inaccuracy in every instance.”
OpenAI reserves the right to provide personal information to third parties, generally without notice to the user, so your personal information could be spread to actors in OpenAI’s economic infrastructure and is very difficult to control.
Misuse of your personal information – what are the risks?
It is reasonable to assume that OpenAI will not knowingly and willfully set out to abuse your personal information because they have to adhere to strict regulations such as GDPR, where misuse could result in fines of hundreds of millions of dollars.
The biggest uncertainty is linked to how the system responds to input in combination with the system’s “learning” abilities.
If asked the “right” question, the system can expose personal information, and may combine information about a person, e.g. a person’s name, with characteristics and histories that are untrue, and which may be very unfortunate for that individual. For instance, asking the system something about a person by name, can result in an answer that “transforms” a credit card fraud investigator to be a person adhered to credit card scam.
Takeaways
Using generative AI systems, for example ChatGPT, is like chatting with a “black box” – you never know how the “box” utilizes your input. Likewise, you will never know the sources of the information you get in return. Also, you will never know if the information is correct. You may also receive information about other individuals that you shouldn’t have, potentially even sensitive and confidential information.
Similarly, other individuals chatting with the “box”, may learn about you, your friends, your company etc. The only way to avoid that, is to be very careful when writing your prompts.
That said, OpenAI has introduced some control features in their ChatGPT where you can disable your chat histories through the account settings – however the data is deleted first after 30 days, which means that your data can be used for training ChatGPT in the meantime.
You can object to the processing of your personal data by OpenAI’s models by filling out and submitting the User Content Opt Out Request form or OpenAI Personal Data Removal Request form, if your privacy is covered by the GDPR. However, when they say that they reserve the right “to determine the correct balance of interests, rights, and freedoms and what is in the public interest”, it is an indication of their reluctance to accept your request. The article in Wired is recommended in this regard.
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought about your specific circumstances.
In our blog post on 23 October 2022, we referred to the Data Protection Authorities (DPAs) of Austria, Denmark, France, and Italy who were concluding that the use of Google’s Universal Analytics (UA or GA3) is not compliant with the EU’s General Data Processing Regulation (GDPR).
The reason for this is that the use of GA3 implies that personal data is transferred to the US, which at that point in time was not on the EU’s list of countries that have adequate level of protection of personal data. This means that the US was not fulfilling the requirements set by the EU/GDPR regarding ‘the protection of fundamental rights and freedoms of natural persons’, which is a key expression in the GDPR.
Furthermore, the Norwegian DPA (Datatilsynet) had up until 23 October 2022 received one (1) complaint regarding Google Analytics. Before any final decision is made, they have toconfer with other supervisory authorities in the EEA that also have received similar complaints, according to GDPR Article 60 (One-Stop-Shop mechanism).
(We regret that links in italics in this article point to web pages in Norwegian.)
Universal Analytics (GA3) replaced by GA4
In October 2020, Google released Google Analytics 4, the new version of Google Analytics. In March 2022, Google announced that the Google Universal Analytics tool will be sunset in July 2023 and that Google would only provide the GA4 tool after 1 July 2023.
The Danish DPA have analyzed the GA4 regarding privacy, and concludes on their website that even if improvements have been made, it is still the case that “law enforcement authorities in the third country can obtain access to additional information that allows the data from Google Analytics to be assigned to a natural person.” That said, GA4 is illegal in terms of the GDPR because servers in the US are involved in the process, as long as an adequacy decision EU/US is not made.
The Norwegian DPAdecision
Norwegian DPA reports on their website 27 July 2023 that they have concluded on the complaint mentioned above. The complaint stems from the noyb who lodged it against 101 European websites to the data supervisory authorities in the EEA for the use of GA. One of these was the Norwegian telecom-company Telenor, who at that time was using GA.
The conclusion is that personal data then was transferred to the US in violation of the GDPR, Article 44. In other words, the use of Google Analytics was illegal. Because Telenor discontinued use of GA on January 15, 2021, the Norwegian DPA in a letter on 26 July 2023 finds that a reprimand “to be an adequate and proportionate corrective measure”.
The Norwegian DPA relies on the Danish authority by claiming that the conclusion will be the same regardless of whether Google Analytics 3 or 4 has been used (see above).
What about adequacy EU/US?
On 10 July 2023 the European Commission adopted its adequacy decision for the EU-US Data Privacy Framework and announced a new data transfer pact with the United States.
Accordingly, companies from the EEA area should be able to legally use GA as long as Google enter into a so-called Standard Contractual Clauses that provide data subjects with a number of safeguards and rights in relation to the transfer of personal data to Google LLC (Limited Liability Company) in the US.
However there is a big “but”: Max Schrems at noyb writes: “We have various options for a challenge already in the drawer, …. We currently expect this to be back at the Court of Justice by the beginning of next year. The Court of Justice could then even suspend the new deal while it is reviewing the substance of it.”
At Runbox we are always concerned about data privacy – “privacy is priceless” – and we put some effort into keeping ourselves updated on how the EU’s General Data Protection Regulation (GDPR) affects privacy related issues.
That’s because we want to be prepared in case something happens within the area that will affect the Runbox organization, our services, and consequently and most important: our customers.
Update 2023-08-06
On 10 July the European Commission adopted its adequacy decision for the EU-US Data Privacy Framework and announced a new data transfer pact with the United States. See the full text here: COMMISSION IMPLEMENTING DECISION.
The Austrian non-profit organization NOYB, chaired by Maxmillian Schrems, stated:
“We now had ‘Harbors’, ‘Umbrellas’, ‘Shields’ and ‘Frameworks’ – but no substantial change in US surveillance law. The press statements of today are almost a literal copy of the ones from the past 23 years. Just announcing that something is ‘new’, ‘robust’ or ‘effective’ does not cut it before the Court of Justice. We would need changes in US surveillance law to make this work – and we simply don’t have it.“
“We have various options for a challenge already in the drawer, although we are sick and tired of this legal ping-pong. We currently expect this to be back at the Court of Justice by the beginning of next year. The Court of Justice could then even suspend the new deal while it is reviewing the substance of it.” [source]
The last words are obviously not said.
Originally published 2023-03-19
The case of EU-US data transfer is highly relevant because Runbox has an organizational virtual modus operandi, and that this could lead to an opportunity to involve consultants that are residing in the US. We know that many of our customers are as concerned as we are about data privacy, so we believe it is pertinent to share our findings.
In blogpost #15 in our series of the GDPR we referred to the Executive Order signed by US President Joe Biden on 07 October 2022. This happened six months after the US President and the President of the EU Commission Ursula von der Leyen with much publicity signed the Trans-Atlantic Data Privacy Framework on 25 March 2022.
Joe Biden and Ursula von der Leyen at a press conference in Brussels. [Xavier Lejeune/European Commission]
In this blog post we will take a closer look at the Trans-Atlantic Data Privacy Framework, and the process thereafter.
Trans-Atlantic Data Privacy Framework
The objective of the Framework is to (re)establish a legal (with regards to the GDPR) mechanism for transfers of EU personal data to the United States, after two former attempts (Safe Harbour and Privacy Shield) were deemed illegal by the Court of Justice of the European Union (CJEU).
The Framework ascertains United States’ commitment to implement new safeguards to ensure that ‘signals intelligence activities’ (SIGINT, intelligence-gathering by interception of signals) are necessary and proportionate in the pursuit of defined national security objectives. In addition, the Framework commits the US to create a new mechanism for EU individuals to seek redress if they believe they are unlawfully targeted by signals intelligence activities.
Following up the 25 March 2022 Biden–von der Leyen agreement, the US president signed on the 7 October 2022 the Executive Order (EO) ‘Enhancing Safeguards for United States Signals Intelligence Activities’.
US compliance with the GDPR
Subsequently a process was initiated on 13 December 2022 within the EU Commission to assess whether the US, after the implementation of the EO, will meet the requirements qualifying the US to the list of nations that is compliant with the GDPR Article 45 “Transfers on the basis of an adequacy decision”. That is, whether the European Commission has decided that a country outside the EU/EEA offers an adequate level of data protection. To those countries, personal data may be transferred seamlessly, without any further safeguard being necessary, from the EU/EEA.
Inclusion of the US on that list is of course very important, not least for companies like Facebook and Google, and US companies offering cloud-based services as well. The Court of Justice of the European Union (CJEU) has deemed earlier transfer schemes (Safe Harbour and Privacy Shield) illegal, so “the whole world” is waiting for the EU Commission’s adequacy decision.
This came, as a draft, 14 February 2023 where the Commission concludes (page 54) that “… it should be decided that the United States ensures an adequate level of protection within the meaning of Article 45 of Regulation (EU) 2016/679, …)
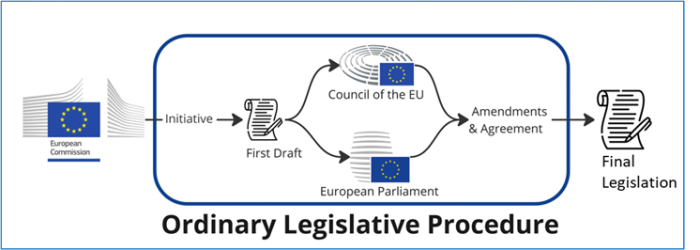
(The figure below illustrates the “road” for legislative decisions in the EU. A more comprehensive description of the legislative procedure can be found here.)
However, the same day, 14 February 2023, the Committee on Civil Liberties, Justice and Home Affairs of the European Parliament concludes ” .. the EU-US Data Privacy Framework fails to create actual equivalence in the level of protection; ..” and “..urges the Commission not to adopt the adequacy finding;”.
Incompatible legislative frameworks
There are two important arguments, among others, behind the Commission’s conclusion: 1) There is no federal privacy and data protection legislation in the United States, and 2) the EU and the US have differing definitions of key data protection concepts such as principles of necessity and proportionality (for surveillance activities etc.), as pointed out by the Court of Justice of the European Union (CJEU).
Shortly thereafter, on 28 February 2023, the European Data Protection Board (EDPB) made public their opinion on the decision of the EU Commission regarding the adequacy. The EDPB has some concerns that should be clarified by the Commission, for instance relating to exemptions to the right of access, and the absence of key definitions.
Furthermore, the EDPB remarks that the adequacy decision is only applicable to US organizations which have self-certified, and that the possibility for redress provided to the EU data subjects in case of violation of their rights is not clear. “The EDPB also expresses concerns about the lack of a requirement of prior authorization by an independent authority for the collection of data in bulk under Executive Order 12333, as well as the lack of systematic independent review ex post by a court or an equivalently independent body.”, as stated in Opinion 5/2023.
The next step in the process is voting over the Commissions proposal in the European Parliament, probably in April, and thereafter the adequacy decision must be approved by all member states, before the EU Commission’s final decision.
The Commission may set aside the results of the voting in The Parliament, but one should expect that the critics from The Committee on Civil Liberties, Justice and Home Affairs, and the concerns of EDPB, will impact the implementation of the Framework.
Here it would be prudent to recall the statement made by the Austrian non-profit organization NOYB, chaired by Maxmillian Schrems: “At first sight it seems that the core issues were not solved and it will be back to the CJEU sooner or later.”. This refers to the verdicts of the CJEU (Court of Justice of the European Union) condemning the former frameworks Safe Harbour and Privacy Shield – the verdicts bearing the name Schrems I and Schrems II, respectively.
Bottom Line: The final outcome of the process is unclear, but in any event we have to wait for the final decision of the EU Commission.
The content of this article is intended to provide a general guide to the subject matter. Specialist advice should be sought regarding any specific circumstances.
Four European Data Protection Authorities (DPAs) have thus far concluded that the transfer of personal data to the United States via Google Analytics is unlawful according to the General Data Protection Regulation (GDPR).
It is quite certain that other European DPAs, including the Norwegian Data Protection Authority, will follow suit because all members of EU/EEA are committed to comply with the GDPR.
Website analytics vs privacy
Everyone who manages a website is (or should be) interested in the behavior of users across web pages. For this purpose there are analytics platforms that measure activities on a website, for example how many users visit, how long they stay, which pages they visit, and whether they arrive by following a link or not.
To help measure those parameters (and a lot of others) there exists a market of web analytics tools of which Google Analytics (GA), launched in 2005, is the dominant one. In addition, GA includes features that support integration with other Google products, for example Google Ads, Google AdSense and many more.
The use of GA implies collecting data that is personal by GDPR definition, for instance IP-addresses, which can be used to identify a person even if done in an indirect way. GA may use pseudonymization, using their own identifier, but the result is still personal data.
The fact that data collected by GA, of which some data is personal, is transferred to the USA and processed there, has brought the DPAs of Austria, Denmark, France, and Italy to conclude that the use of Google Analytics is not compliant with the GDPR.
None Of Your Business
This conclusion has been reached after complaints submitted by the Austrian non-profit organization NOYB (“my privacy is None Of Your Business”) to a number of European DPAs.
The complaints are based on the Court of Justice of the European Union (CJEU) concluding that the transfer of personal data to the US, without special measures, violates the GDPR.
According to NOYB the Executive Order signed by US President Joe Biden recently will not solve the problem with EU-US data transfers with regards to the potential for mass surveillance.
DPAs on the case
The Danish DPA writes that even if Google has indicated that they have implemented such measures, these measures are not satisfactory in order “to prevent access to transferred personal data by US law enforcement authorities”.
The Norwegian DPA has thus far received one complaint regarding Google Analytics, and they are saying on their web site that the case is being processed.
They “will place great emphasis on what other countries have come up with”, they say in an email conversation.
Runbox will continue following these developments and keep you updated.
Note: Runbox used GA during a short period between 2011 and 2013. When we became aware of how Google collects data and how they potentially could use these data across their various services, we terminated the use of GA in October 2013. Since then we use only internal statistics to monitor our service and visitor traffic on our web site, and these data are not shared with anyone in accordance with our Privacy Policy.