Across Europe, conversations are taking place about reducing dependence on US tech and moving towards European technology solutions. In a world which at times feels like it has shifted on its axis, it’s becoming clear that this movement is about more than just technology. The shift away from US tech is about reducing reliance and protecting infrastructure, but also about protecting the fundamental principles that define us as a society. Europe’s focus on data privacy, transparency, and democratic values can often feel in direct conflict with the US approach. In this article, we look at what’s at stake and what Europe is doing about it.
As a Norwegian company, Runbox is occasionally asked how the U.S. CLOUD Act affects our users—and the answer is simple: it doesn’t. Unlike U.S.-based providers, we own our servers and operate under Norwegian law, ensuring your emails and personal data are fully protected by Norwegian law and GDPR. The CLOUD Act has no jurisdiction over Runbox or your information. Read on to learn how we keep your data safe.
Recent reports reveal that some companies are handing over user data when served with a subpoena by authorities. At Runbox we monitor this trend with concern and want to take the opportunity to make it clear that we will not disclose user data to anyone unless certain very specific and stringent criteria are met.
A subpoena, warrant or request from any government or foreign agency is not enough to meet our requirements. If an entity requests access to any user data, Runbox will by principle respond by requesting a Norwegian court order pursuant to the Norwegian Criminal Procedure Act before disclosing any information.
Read on to learn how Norwegian privacy law protects your data and why it’s your best defense.
As a privacy-focused email service based in Norway, we believe that protecting the right to privacy isn’t just about safeguarding data. It’s also about defending the very essence of democracy. Privacy and free expression are what let us speak freely, challenge authority, and engage in society without fear – democracy can’t thrive without them. And without our active participation, the structures that uphold our freedoms lose their strength, and the principles we value start to disappear.
Without privacy, how safe is your right to speak your mind? How fair is the system if your personal information can be used against you? How free are you to take part in your community if you’re always looking over your shoulder? Privacy isn’t just another right – it’s the cornerstonethat protects all our other rights.
Because democracy is more than just the rule of law, free and fair elections or independent courts. It is also about the right to privacy. When privacy is weakened, everything else we value in a democracy starts to wobble. That’s why we at Runbox don’t just see privacy as a feature – we see it as a commitment to the principles that keep societies open, fair, and free.
In late 2025, reports emerged that Google had enabled its Gemini AI by default for Gmail, Chat, and Meet users, allowing it to analyze private communications – often without explicit user consent. While Google maintains that Gmail content is not used to train its public Gemini AI models, it can still scan and process emails, attachments, and other data for personalization features like summarizing and drafting replies.
The controversy centers on how this access was enabled by default, the lack of clear user notification, and the complexity of opting out, sparking concerns about privacy and transparency. Here’s what’s happening, why it matters, and what you can do.
Are you tired of relying on big tech companies for your email needs? Do you want to take back control over your online presence and protect your personal data? Meet Runbox, a Norwegian email provider providing a secure, sustainable, and flexible email solution that puts you first. With us, you can rest assured that your usage data is never tracked, sold, or used to serve unwanted ads in your inbox – ensuring a truly private and secure digital experience.
Many of our users have long relied on Outlook as their email client, but recent changes to how data is managed raise important privacy and control concerns. While the interface may look familiar, Microsoft has fundamentally changed how the new Outlook works behind the scenes — including how your emails are stored and accessed. In this article, we look at what’s changed and why you might want to consider other options.
Thinking about stepping away from Big Tech but not sure where to turn? You’re not alone. More and more people are questioning how their data is used — and tired of being tracked, targeted, and profiled for profit. Some are choosing European services protected by GDPR, while others turn to open source tools that put transparency first. We’ve put together a list of solid alternatives for everything from email to maps.
Privacy concerns in the online world aren’t new. We already know that big tech collects our personal data through “free” services, that data brokers profit off that data, that AI is scraping our social media for added profiling, and that governments utilize various surveillance technologies. But with the rapidly changing global landscape of threats to freedom of expression and personal liberties, there is a new level of concern for the need for privacy. Here, we point to some recent developments that may have an impact on privacy protections and personal data. Below you will also find a list of safe and private alternative services.
In our previous post on the AI Act, we concluded with a remark concerning the AI Act and the GDPR (General Data Protection Regulation): Are the two regulations aligned, or are there contradictions?
In this post we want to explore this question.
NOTE: When speaking about personal data and data subjects in the following, it is in the context of the GDPR. In addition, our concerns about AI and GDPR are mainly directed at general-purpose AI systems (GPAI-systems)where large amounts of (scraped) data is used to train the GPAI-modelon which the GPAI-system is built. (See box F below for exact definitions.)
The scope of the AI Act is comprehensive – it applies to any actor and user of AI systems within the jurisdiction of the European Union law, regardless of the actor’s country of residence.
As the GDPR, the AI Act is a regulation, contrary to a directive, which means that EU member countries have to implement it in their own legislation with only minor adaptive changes. The AI Act has EEA (European Economic Area) relevance as well, which means that the AI Act has to be implemented in Norwegian legislation – as the GDPR was.
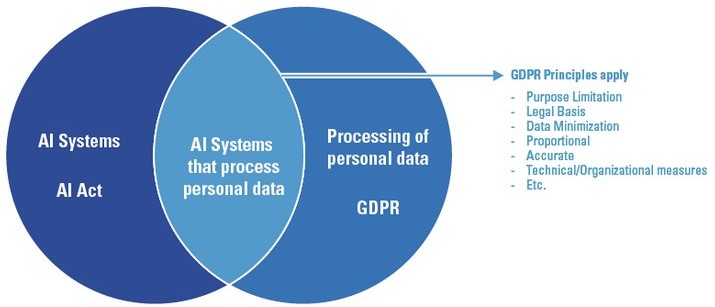
Intersection between AI and Privacy regulation [Source]
The diagram shown illustrates the situation: There are some obvious overlaps because AI systems may process personal data, and so GDPR principles apply.
On that basis, we could say “end of story” and “case closed”. However, there are some differences and potential conflicts, making it worthwhile to spend some time on the issue.
It is beyond the scope of this blog post to cover all aspects of the issue at hand, so let’s discuss the fundamentals, with what’s most relevant to Runbox in mind.