It’s been a while since our last Runbox 7 update post, and we wanted to share what we’ve been working on behind the scenes. Some of these are small quality-of-life improvements, a few are bug fixes that should make daily use smoother, and others are bigger updates to areas like payments and to our underlying framework — setting the stage for more updates in the near future.
💡 To enable the new features, please ensure that Runbox 7 is updated by reloading it in a web browser or restarting it on your phone.
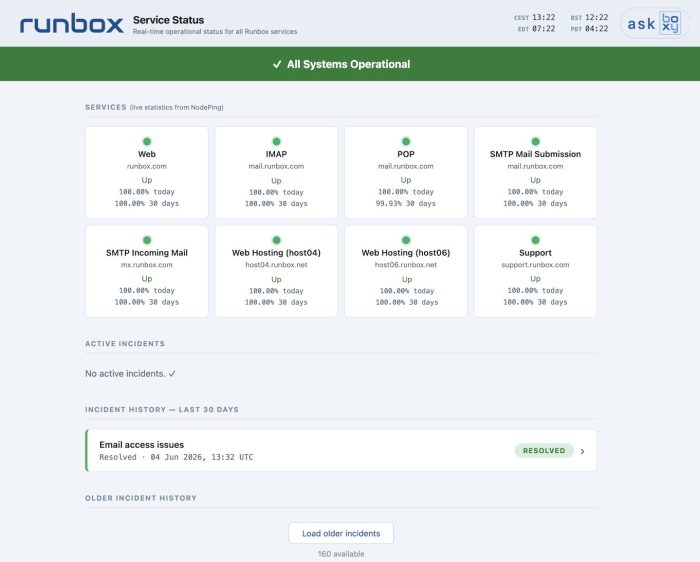
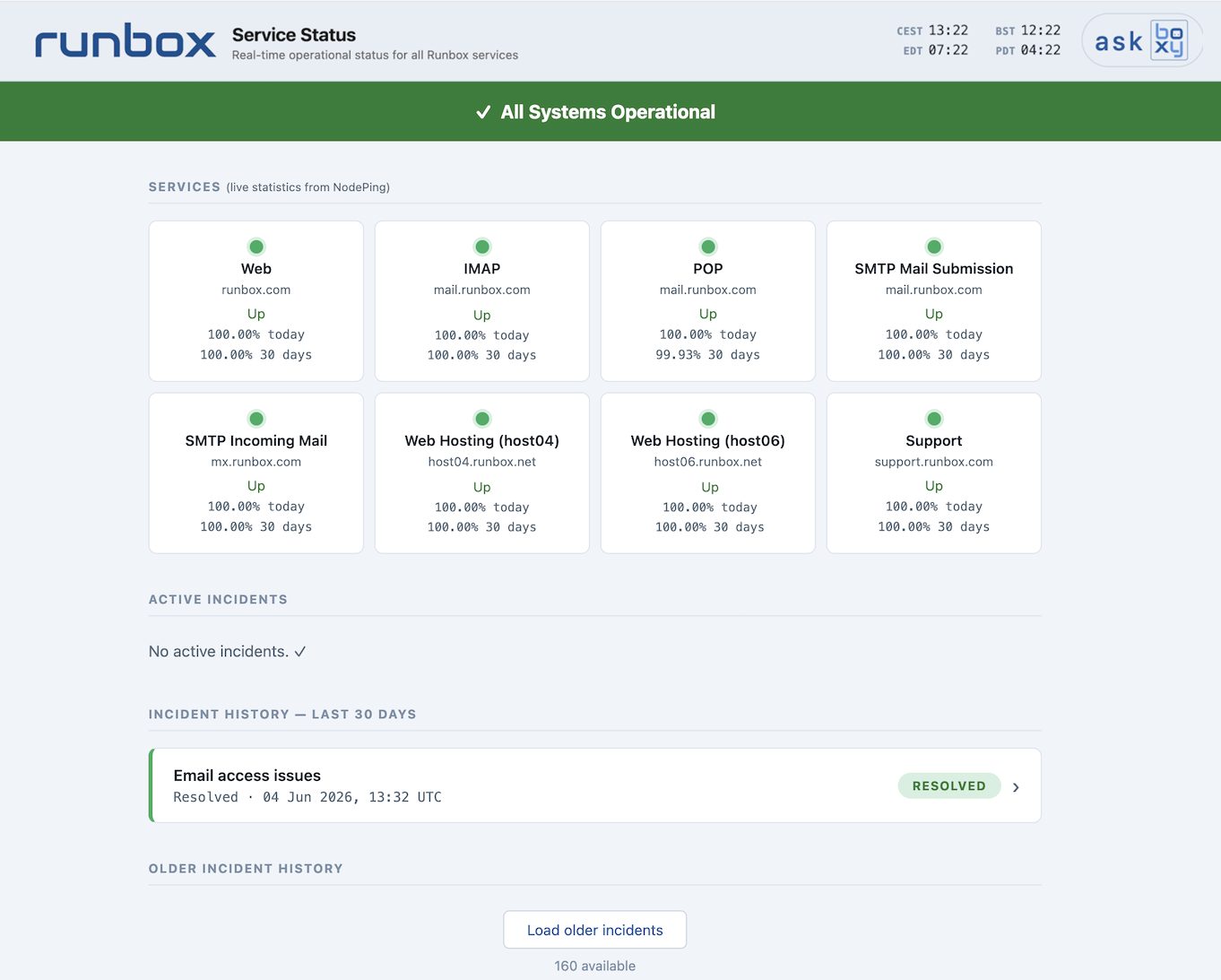
Updated Status Page
We have given our status page a fresh new look at status.runbox.com. An important change is that the latest updates now appear at the top of each incident post so that we can communicate better. Previously new updates were added at the bottom, and it was easy to miss updates unless you actively clicked through. The page shows live service status at a glance, with a colour-coded banner indicating overall health. Timestamps across four time zones let you always know what’s happening no matter where you are. The new status page also integrates with Boxy, our support assistant, which can answer service-status questions directly.